불균형 데이터 처리를 위한 7가지 Over Sampling 기법들
본 포스트는 아래 글을 번역한 것입니다.
https://towardsdatascience.com/7-over-sampling-techniques-to-handle-imbalanced-data-ec51c8db349f
7 Over Sampling techniques to handle Imbalanced Data
Deep dive analysis of various oversampling techniques
towardsdatascience.com
불균형 데이터를 처리하는 것은 모델을 트레이닝 할 때 직면하게 되는 주요한 과제이다. 분류 대상인 레이블의 균형은 분류 모델을 트레이닝 하는 과정에서 중요한 역할을 하는데, 트레이닝 데이터셋 내의 레이블이 불균형 상태로 존재하는 경우, 모델은 트레이닝 데이터셋 내의 다수를 차지하는 레이블을 예측하도록 학습되고 이는 편향된 예측으로 이어지게 된다. 신용카드 사기 탐지, 질병 진단, 스팸 감지 등 특수한 상황에 대한 예측을 할 때 특수한 상황 데이터의 부족으로 이런 문제가 존재할 수 있다. 따라서 모델을 트레이닝 시키기 이전에 데이터셋 내에 존재하는 불균형 문제에 대한 처리가 선행되어야 하고, 이를 위한 다양한 기법들이 개발되어 있다. 그 기법 중 일부는 over sampling, under sampling 혹은 이 둘의 조합 등으로 만들어져 있는데, 본 포스트에서는 over sampling을 활용한 7가지 방법을 알아본다.
본문 전체에서 사용하는 데이터를 oversampling 과정 없이 로지스틱 회귀 모델을 활용해서 성능을 측정한 결과는 다음과 같다.

1. Random Over sampling
가장 간단한 방식의 oversampling기술로 기존 불균형 데이터셋의 레이블의 균형을 맞출 수 있음. 이 방법은 소수 레이블에 해당하는 데이터 샘플을 복제하는 방식으로 이루어지므로 정보 손실이 없는 특징이 있다. 그런데 해당 방식의 특성 때문에 복제 되는 레이블이 동일한 정보에 대해 overfitting 되기 쉽다는 단점을 가진다.

2. Smote
Random oversampling 과정에서 과적합 되는 경향을 보이는 문제가 있었는데, 이 부분도 함께 해결하면서 oversampling 하는 방식이 SMOTE 이다. SMOTE 는 Synthetic Minority Oversampling Technique의 약자로, 데이터셋의 균형을 맞추는 과정에서 새 샘플을 합성해 만드는 방식이다.
SMOTE는 k-nearest neighbor 알고리즘을 이용해서 합성 데이터를 생성하는데, 그 과정은 다음과 같다.
- 가장 가까운 이웃 데이터의 feature vector를 찾는다
- 두 샘플 포인트의 distance를 계산한다
- (2)에서 계산한 distance에 0과 1 사이의 random 값을 곱한다
- (3)에서 업데이트 된 distance에 해당하는 line segment 상에 new point를 찾는다.
- (1-4) 과정을을 feature vector에 대해 반복한다.

3. BorderLine Smote
다수를 차지하는 레이블 (major class point)이 붙어있는 데이터가 주로 위치하는 지역 내에도 소수를 차지하는 레이블로 분류되는 데이터 (minor class point) 샘플이 존재하는데, SMOTE를 사용하게 되면, major class point들이 밀집되어 있는 곳에 minor class point 들의 bridge 가 생성되게 된다. (major class point 밀집 지역에 존재하는 minor class point의 데이터와 그 밖 지역의 minor class point 데이터 사이에서 합성된 sample을 만드는 경우에 두 데이터 사이에 합성된 minor class point가 합성되면서 연결되는 것처럼 보일 수 있는데 이런 현상을 의미하는 것으로 이해) 이런 문제를 해결하기 위해 Borderline Smote 방식이 활용된다.
Borderline Smote 방식에서는 oversampling 하는 대상을 major sample과 minor sample 사이의 borderline 상의 데이터들로 한정한다. 이 방식에서는 minor class point 를 noise point, border point 로 분류하는데, 이웃하는 point의 대부분이 major class point인 경우 noise point로 분류하고, 이웃하는 point에 major, minor class point가 같이 존재하는 경우 border point로 분류한다.
분류된 point 중에서 noise point는 무시, border point 들에 대해서만 데이터 합성을 통해 oversampling 을 진행하게 된다.

4. KMeans Smote
K-means smote 방법은 minority class sample을 "안전한 위치"에 새로 생성하는 방식으로 balancing 을 돕는다. 안전한 위치에 생성하도록 해서 over-sampling 을 통해 noise가 생성되는 것을 방지하고, 효과적으로 imbalance dataset을 보완하도록 한다.
K-means smote는 다음과 같은 과정으로 이루어진다.
- K-means clustering 알고리즘을 활용해서 전체 data에 대해 clustering을 한다.
- Minority class sample을 많이 포함하고 있는 cluster를 선택한다.
- 해당 cluster들 중 minority class sample이 더 퍼져서 분포하는 cluster에 보다 많은 합성된 sample을 할당한다.
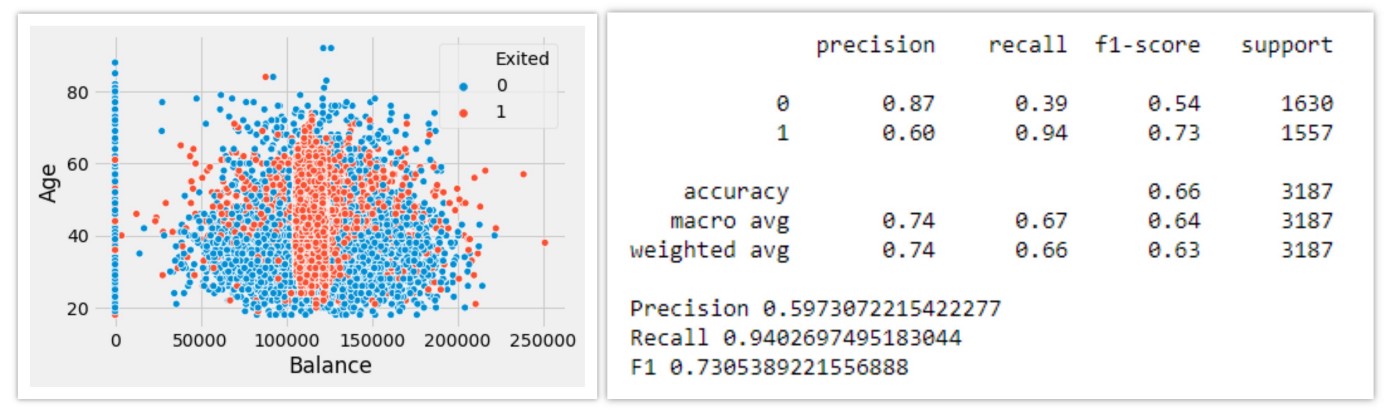
5. SVM Smote
Borderline smote 방식에 변형을 준 것이 SVM Smote이다. Borderline-SMOTE SVM 이라고도 불린다. 이 방식은 SVM 방식을 활용해서 misclassification point를 찾는 과정을 포함하고있다. SVM SMOTE에서 borderline area는 training된 SVM classifier의 support vector에 의해 추정된다. borderline area 추정이 완료되면, 이후에는 해당 area 내의 datapoint을 이용, minor class sample을 합성하는 동일한 과정을 수행함으로써 oversampling을 할 수 있다.
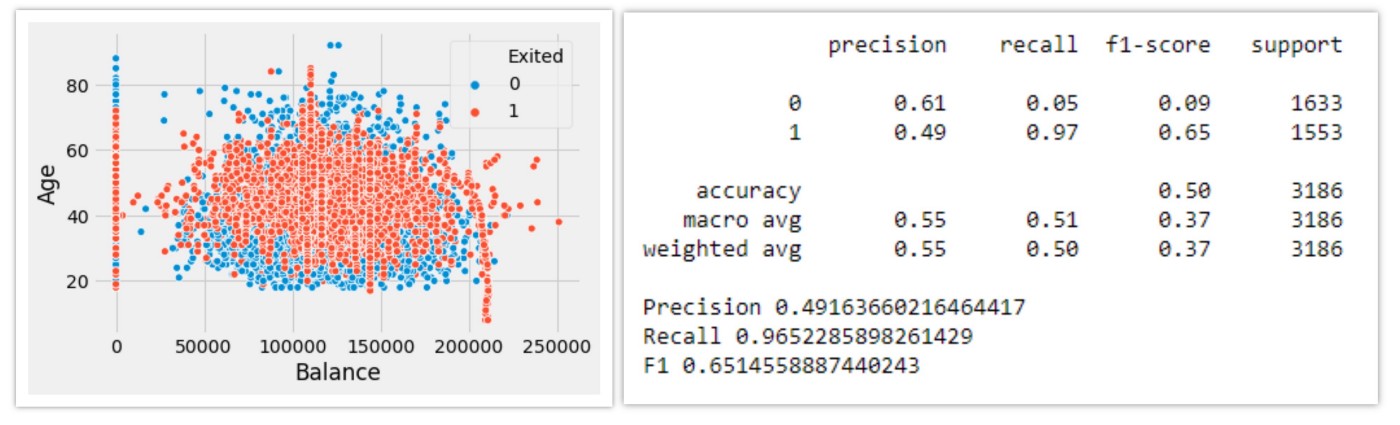
6. ADASYN
Borderline Smote의 한계는 Borderline에 존재하는 데이터만을 새로운 샘플 합성의 reference로 사용하는 지점에서 발생한다. Border region의 datapoint는 minor point 밀집 region의 데이터에 대해서는 극한에 해당하는 관찰값인데, borderline 을 도입하는 방식에서는 borderline 이외 지역에 존재하는 minority class sample은 무시되고 극한에 해당하는 관찰값에 가중치를 두고 새로운 데이터를 합성하는 셈이다. 이러한 문제는 데이터의 밀도를 토대로 데이터를 합성해내는 ADASYN방법을 통해 극복될 수 있다.
합성 데이터의 생성은 minority class의 밀도에 반비례하게 수행된다. 이를 통해 minority class sample이 높은 밀도로 존재하는 지역보다 낮은 밀도로 존재하는 지역에서 보다 많이 합성될 수 있게 한다.

7. Smote-NC
앞서 언급한 SMOTE oversampling 기법의 경우, 연속형 데이터 상에서 작동하는데, 범주형 데이터에 대해서 oversampling을 수행할 수 있도록 SMOTE를 변형한 SMOTE-NC가 있다. 범주형 데이터에 대한 one-hot encoding을 통해 SMOTE를 사용할 수 있는 형태로 변환하는 방법도 존재하지만 이 과정에서 데이터의 차원이 증가하는 문제가 존재하고, 범주형 데이터를 특정한 실수로 할당하는 과정에서는 불필요한 정보들이 생성될 수 있다는 단점이 존재한다. 따라서 혼합 데이터를 가지는 경우에는 SMOTE-NC를 사용해야 한다. SMOTE-NC는 범주형 데이터를 별도로 표기하고, SMOTE는 합성 데이터를 생성하는 대신 resampling을 수행하게 된다.

결론
불균형 데이터셋을 모델링하는 것은 모델을 트레이닝 하는 과정에서 발생하는 주요 과제로 위와같은 oversampling 기술을 활용해 모델 성능을 꾀할 수 있다. 본 포스트에서 논의된 것 외에도 불균형 데이터셋으로 모델을 트레이닝 하는 경우 random undersampling, SMOTEENN, SMOTETomek 등과 같은 oversampling 기술, oversampling - undersampling의 조합 등을 활용해 성능을 향상시킬 수 있다.
참고문헌
[1] Imblearn documentation: https://imbalanced-learn.readthedocs.io/en/stable/api.html#module-imblearn.over_sampling